Migration du legacy : Comment passer du constat technique à la décision business ?
Les entreprises ne se réveillent pas un matin avec l’envie soudaine de migrer un système déjà bien en place. La migration s’impose d’elle-même le jour où le système devient incapable de répondre aux besoins du marché.
Les développeurs sont en général les premiers à constater les symptômes d’un legacy fragilisé par les années. Mais le diagnostic ne suffit pas pour convaincre l’organisation d’investir des mois de travail à le soigner.
Ce qui bloque, ce n’est pas un problème de légitimité ou de crédibilité technique.
C’est un problème de langage.
Donner l’alerte avec les bons mots
Crier au secours dans une langue étrangère, c’est s’assurer que ceux qui nous entourent mettront plus de temps à réagir. Cela paraît évident et pourtant, c’est une erreur classique.
La technique comprend les risques d’une architecture mal structurée et des règles métiers mal implémentées. Mais ces arguments ne sont pas aussi limpides et convaincants pour le business.
La scène est classique :
Ce que la technique dit.
“Le code est difficile à maintenir, nous avons trop de dette technique. Il faut prévoir un refacto.”
Ce que le business entend.
“Je veux passer mes prochains mois à mettre un coup de pinceau dans mon code”
Raté. La proposition n’a pas eu l’effet escompté. En revanche, un message comme celui-ci aurait eu bien plus d’impact :
“On perd 10 jours-hommes par mois à corriger des régressions au lieu de livrer des features.”
Ce que le business comprend et ce qui déclenche l’action, ce sont des données mesurables. Il faut passer de la plainte technique à la perte financière ou à l’impact business.
Nul besoin de lancer un audit sur tout le système. Les données les plus parlantes sont déjà à portée de main, dans les outils du quotidien :
- Le ratio “Run vs Build” : ouvrir le backlog des 3 derniers mois et comparer les tickets. L’équipe se concentre-t-elle sur la réparation ou sur l’innovation ?
- La fragilité du système : relever le nombre de régressions après chaque mise en production. Combien de développements provoquent des effets de bord impactant pour le business ?
- Le coût de l’onboarding : mesurer le temps passé par un nouveau développeur avant d’être autonome sur le legacy. Quel est le temps passé à déchiffrer plutôt qu’à produire ?
- L’écart de performance entre deux modules : mesurer le temps de développement entre un module legacy et un plus récent. Peut-on dire que le code n’est plus seulement moche mais qu’il est devenu un frein ?
Un chiffre isolé, ça se discute. On peut toujours trouver une excuse. Un sprint qui s’est mal passé, une release un Vendredi, Mercure en rétrograde... En revanche, une courbe qui s’effondre, c’est une alerte que personne ne peut ignorer.
Au lieu de relever une métrique à un instant T, on compile les données sur plusieurs mois pour tracer une trajectoire, et on la prolonge. Simple et pourtant efficace. C’est cette projection que l’on pose sur la table :
“Aujourd’hui c’est tenable. Dans six mois, on ne livre plus rien.”
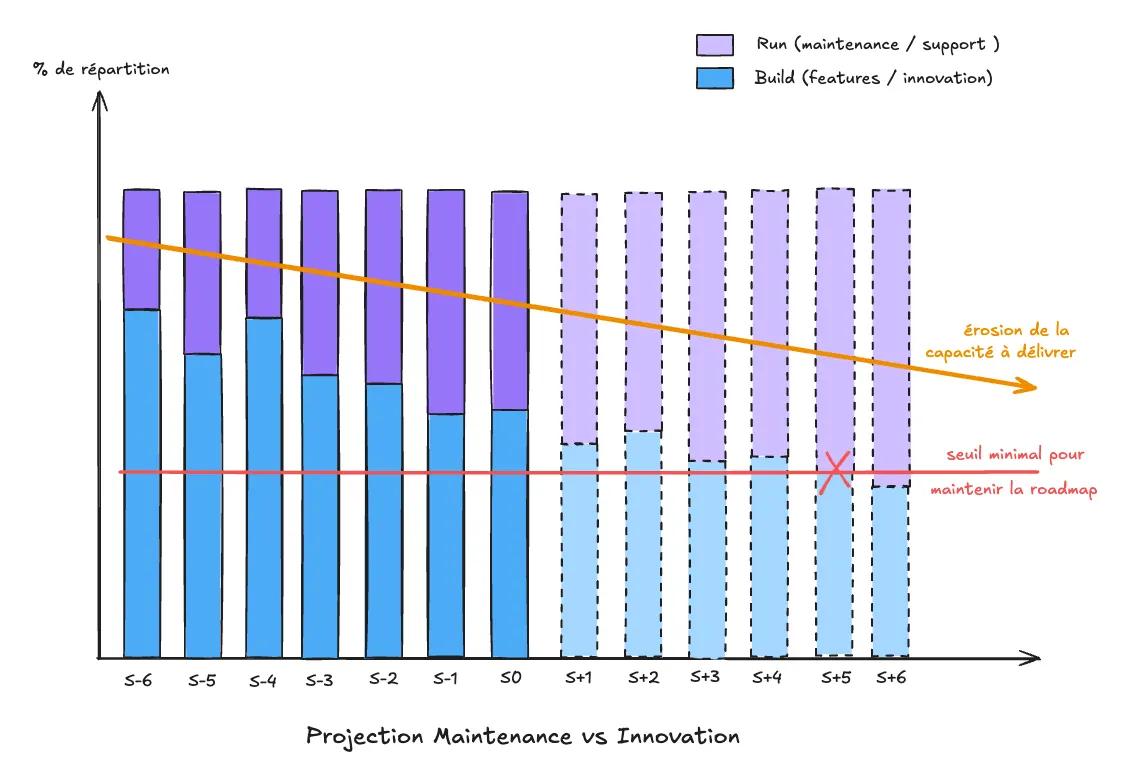
A ce stade, ce n’est pas une migration complète que l’on demande. Ce dont on a besoin, c’est du temps pour analyser et pour réaliser un POC (Proof of Concept). Une demande mesurée, peu risquée et facile à accepter.
L’enjeu est clair : réduire l’incertitude avant de s’engager davantage.
Valider l’intuition par les faits
Le dialogue est rétabli, la technique et le business se comprennent. Le feu vert a été donné pour investiguer. Il faut maintenant prouver qu’une solution existe.
Faire l’état des lieux
Le système est en production, les utilisateurs sont présents, l’équipe a ses habitudes et le budget n’est pas illimité. Autant de contraintes qui semblent bloquer le projet avant même qu’il commence.
Les contraintes sont souvent perçues comme des obstacles alors que c’est l’inverse. Plus la liberté est réduite, plus on devient créatif. Faire l’état des lieux, c’est rendre le terrain prévisible. Et un terrain prévisible, c’est un terrain sur lequel on peut établir une stratégie.
 “C’est un monde entier de seulement 64 carrés. Je me sens en sécurité. Je peux le contrôler, je peux le dominer. Et c’est prévisible.” Le Jeu de la Dame, Beth Harmon — illustration générée par IA"
“C’est un monde entier de seulement 64 carrés. Je me sens en sécurité. Je peux le contrôler, je peux le dominer. Et c’est prévisible.” Le Jeu de la Dame, Beth Harmon — illustration générée par IA"
Réaliser cet état des lieux demande de prendre du recul et d’adopter une vision d’ensemble :
- Quel est l’état du système actuel ?
Définir ses capacités réelles, ses limites critiques et les mises à jour techniques inévitables. - Quelles sont les contraintes non négociables ?
Identifier les fonctionnalités qui doivent être conservées à tout prix et les implémentations intouchables pour le moment. - Quelles sont les compétences de l’équipe ?
Choisir une nouvelle techno est tentant, mais quel est l’intérêt si personne ne peut la faire évoluer ? Évaluer l’effort réel de montée en compétences. - Quel est le cadre business actuel ?
Quels sont les moyens financiers et humains ? Quelle est la charge de travail prévue sur le produit en parallèle ? Les possibilités ne sont pas les mêmes si on migre tout en livrant trois features majeures.
Cette cartographie n’est pas une simple liste, c’est une boussole qui va guider chaque décision à venir.
Le POC pour démontrer
L’état des lieux est posé, une direction commence à se dessiner. Pour la valider, on réalise un POC (Proof of Concept).
L’erreur classique est de vouloir prouver que la migration entière est possible. C’est trop vaste, trop flou, et c’est le meilleur moyen de s’épuiser avant d’avoir commencé. Un bon POC ne répond pas à toutes les questions, il répond à une question précise.
Le choix du périmètre doit être stratégique :
- Représentatif mais pas critique : On veut de la complexité réelle, mais on ne veut pas paralyser la boîte en cas d’erreur.
- Rapide mais crédible : Il doit être assez consistant pour démontrer que l’approche fonctionne, mais assez petit pour être terminé en quelques jours.
L’objectif n’est pas de livrer du code parfait, mais de se confronter aux premières frictions. On cherche à mesurer l’effort réel et à faire remonter les problèmes que l’on n’avait pas anticipés. Le legacy réserve toujours son lot de surprises et mieux vaut les découvrir maintenant. On ne supprime pas le risque, on l’anticipe.
Ce POC n’est pas qu’une demo technique, il peut devenir un outil d’adhésion. Le présenter à l’équipe et recueillir leurs critiques accentuent les chances de réussite : si l’équipe ne croit pas au POC, ils ne croiront pas à la migration.
Une fois cette étape validée, on n’arrive plus devant le business avec une idée, mais avec une preuve.
Revenir avec une stratégie
A cette étape, la posture a évolué. Le ressenti a laissé place au concret : l’état des lieux est posé, les contraintes sont identifiées, le POC est solide et les premières frictions sont connues.
La cible à atteindre se précise, c’est bien. Mais quel est le plan pour y parvenir ? En réalité, il n’y a que deux chemins.
Tout réécrire : un pari risqué
La première réaction est de vouloir tout effacer pour recommencer. Repartir sur une page blanche pour se libérer de ces fameuses contraintes. La promesse : construire un système parfait sur une stack moderne dans son coin avant de l’échanger contre l’ancien.
C’est ce qu’on appelle la migration “Big Bang”. Sur le papier, ça semble être une bonne idée. Dans la réalité d’une entreprise, c’est un pari extrêmement risqué.
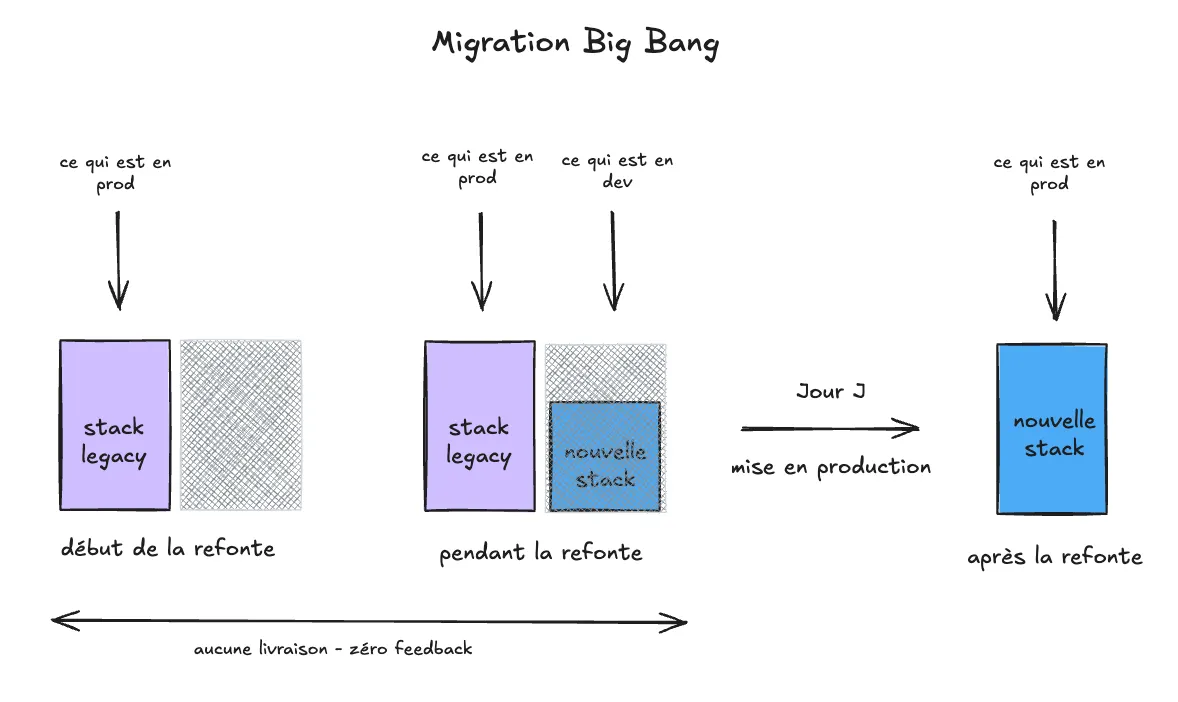
Une réécriture complète prend des mois, voire des années. Le temps devient alors un vrai danger. C’est un “effet tunnel” où :
- le produit attend… : aucun bénéfice concret pendant toute la durée de la réécriture.
- …alors que le marché n’attend pas… : le risque est de livrer un système déjà inadapté, la refonte d’hier devient le legacy d’aujourd’hui avant même d’avoir servi.
- … avec un risque concentré en un point : le jour du déploiement, c’est le “tout ou rien”, sans aucun moyen de tester la réalité du terrain en amont.
C’est également sans compter les coûts et les risques opérationnels liés à cette approche :
- La double maintenance : chaque règle métier ajoutée dans le legacy doit être reportée dans le nouveau système. On travaille deux fois pour le même résultat.
- L’impact humain : on crée deux équipes de développeurs pour gérer le “nouveau” et le “legacy”. La perte de motivation et le turnover sont des risques réels.
Alors, toujours une bonne idée ?
Pourquoi l’itératif (Strangler Fig) ?
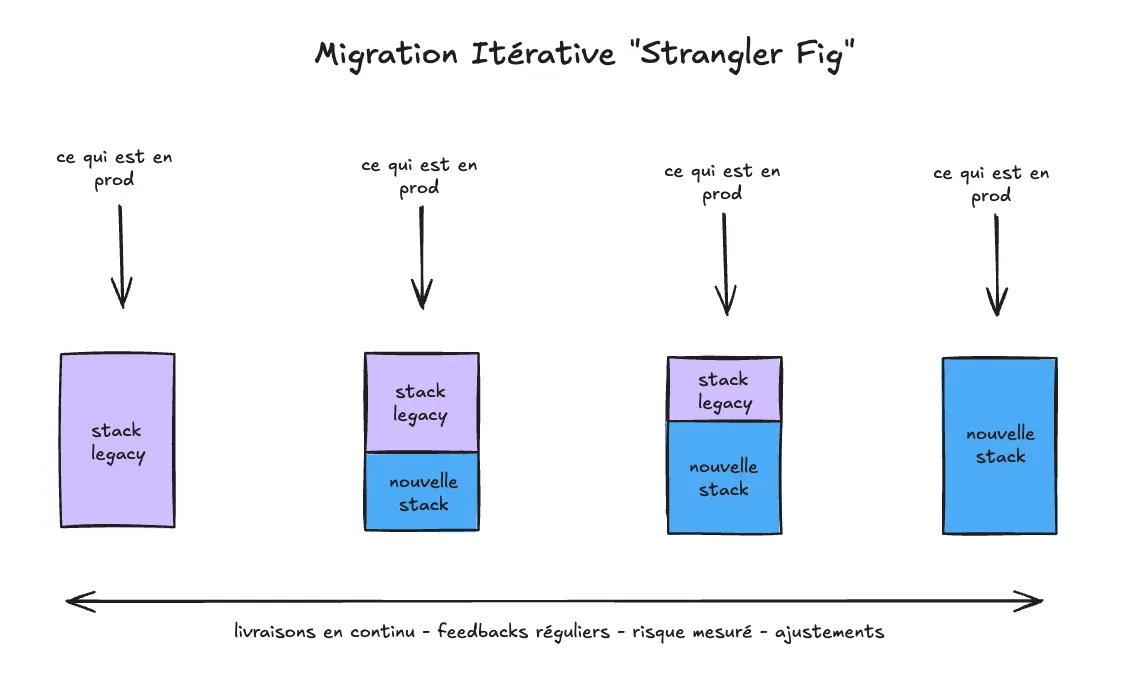
Choisir de migrer par itération, c’est privilégier les bénéfices immédiats et le feedback continu. Au lieu de remplacer tout le système d’un coup, on applique la méthode du "Strangler Fig" : le nouveau système grandit autour de l’ancien, brique par brique, jusqu’à le remplacer complètement.

Racines d’un figuier étrangleur (Strangler Fig), Australie. Photo : John Tann, CC BY 2.0
L’ancien système diminue progressivement jusqu’à disparaître, sans que la production ne s’arrête.
Les avantages concrets de cette approche :
- Zéro effet tunnel : On n’attend pas des mois pour voir si la stratégie fonctionne. Chaque brique migrée apporte une amélioration immédiate et visible. On livre de la valeur réelle à chaque étape.
- Un risque maîtrisé : Si une itération rencontre un obstacle, l’impact est limité à un périmètre. On ajuste, on corrige et on avance.
- Continuité du business : C’est le point clé. On continue de livrer les fonctionnalités attendues par le marché tout en modernisant le socle. On fait évoluer le système sans jamais geler.
- Une équipe unie : Tout le monde travaille sur la même trajectoire. On évite de scinder l’équipe entre le “nouveau” et le “legacy”, puisque la codebase évolue de manière fluide pour tous.
- Apprendre et ajuster : En commençant par les modules les moins critiques, on affine la méthode. On évalue, on simplifie l’existant et on valide les choix techniques au fur et à mesure.
On ne vend pas un miracle, on vend une maîtrise du risque. L’idée est simple : ralentir aujourd’hui pour ne pas s’arrêter demain.
Concrètement, ce qu’on présente au business tient en quatre points : la vision cible (à quoi ressemble le système une fois la migration terminée), le premier périmètre à migrer, une estimation basée sur le POC, et un point d’étape après chaque itération pour ajuster. Pas de promesse sur douze mois, juste une direction claire, un premier pas et un moyen de piloter la suite.
On ne dit plus “il faut migrer”, on dit “voilà la cible et voilà comment l’atteindre”.
Avoir un plan, c’est essentiel. Mais l’exécuter est une toute autre histoire. En pratique, on découvre vite que la réussite d’une migration ne se joue pas uniquement sur les choix techniques. Elle se joue sur la capacité à embarquer une équipe, à gérer les priorités qui changent en permanence, et à prendre des décisions avec des informations incomplètes.
Le Tech Lead jongle entre plusieurs rôles : vendre des gains atteignables au business, engager les développeurs, arbitrer des compromis chaque jour. Les règles de cette partie-là ne figurent sur aucun schéma d’architecture.
Et c’est pourtant là que tout se joue.